
Deep Dive into etcd: Write-Ahead Log, Protocol Buffers and Leader Elections
Welcome back to the second part of our deep dive into etcd, the beating heart of Kubernetes. In the first part, we introduced etcd and its pivotal role in a Kubernetes cluster, illustrating how it stores the state and configuration data while working in close conjunction with the Kubernetes API server. We also gave a hands-on guide on how to navigate etcd's data using etcdkeeper in a Minikube environment.
In this part of the series, we're going to delve deeper into the internals of etcd. We will explore the Write-Ahead Log (WAL) mechanism that ensures the durability of etcd's data, Protocol Buffers (protobuf) which form the basis of etcd's data model, and the leader election process that is a vital aspect of etcd's operation. We'll also demonstrate how to interact with etcd data directly in a Kubernetes cluster using a Go client.
Unraveling etcd's Core: The Write-Ahead Log (WAL)
We kick off the second part of our series by diving straight into the heart of etcd – the Write-Ahead Log, or WAL for short. This is where etcd records all the changes before they get applied to the database. The 'write-ahead' aspect signifies that operations are logged ahead of time, ensuring data integrity and system consistency.
The WAL plays a crucial role in safeguarding your data against failures. If an operation is in progress and a crash occurs, all is not lost. On recovery, etcd replays the entries from the WAL, getting your system back up to speed swiftly and seamlessly.
In the context of etcd, it's this combination of the WAL and the Raft consensus algorithm that provides that superb level of fault tolerance we talked about in Part 1.
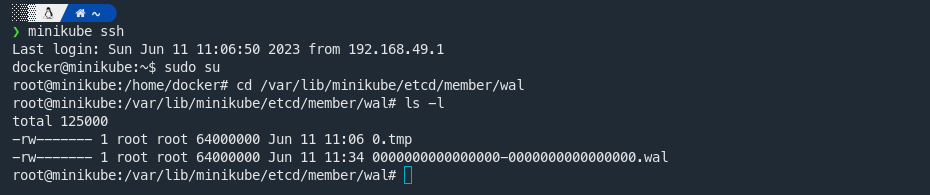
Now, you might be curious to see this WAL in action. In a Minikube environment, you can explore the etcd data directory to find the WAL. Let's take a look:
$ minikube ssh
$ sudo su
# cd /var/lib/minikube/etcd/member/wal
# ls -l
This command will take you to the WAL directory. Here, you'll see a series of files, each representing a segment of the WAL. These files capture a snapshot of the transactions in your etcd cluster, preserving the history of changes that can be used to rebuild your etcd state if needed.
Now let's examine the content of a .wal file
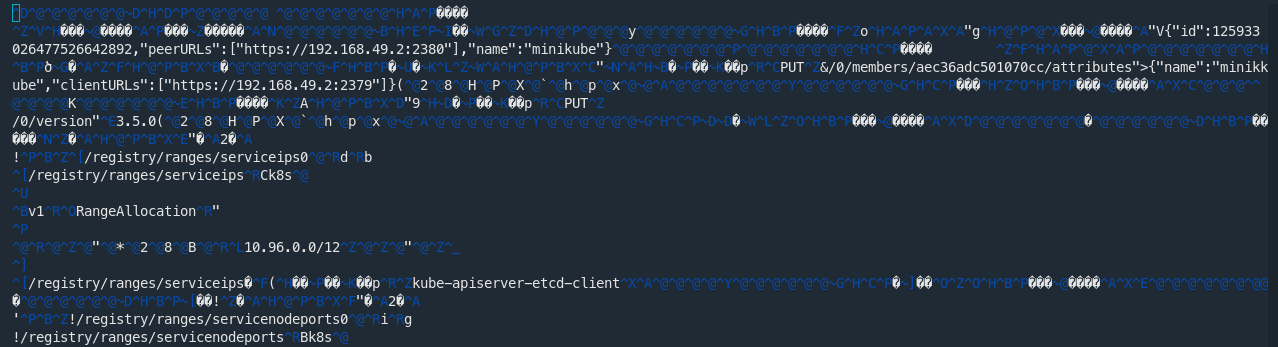
You might also notice a '.tmp' file. This temporary file comes into play during the writing process. When etcd writes entries, it first does so to this temporary file. Once the write operation is successful, the tmp file is atomically renamed and becomes the next segment of the WAL. This way, etcd ensures that the main WAL files only contain complete and valid entries, offering an additional protective layer against potential data corruption.
By leveraging the power of the WAL, etcd ensures that your data is safe and your system's state is consistent, no matter what. It's the safety net that lets your Kubernetes cluster operate reliably and smoothly.
Protocol Buffers: etcd's Chosen Data Model
At the core of etcd's efficiency in handling large amounts of data is the use of Protocol Buffers, often shortened to protobuf. Protocol Buffers are a language-neutral, platform-neutral, extensible mechanism for serializing structured data. This format is developed and maintained by Google and is used extensively in their internal data storage and communication.
etcd utilizes Protocol Buffers because they offer a number of benefits. Firstly, they're compact and faster to serialize/deserialize compared to JSON or XML. Second, they're strongly typed and schema-enforced, which makes it harder to make mistakes. Finally, the schema used to serialize the data is required to read it, promoting good documentation and versioning practices.
If you're exploring the etcd database using a tool like etcdkeeper or etcdctl, you may come across data that looks quite strange at first glance. For instance, if you navigate to /registry/pods/default/keepr, you would find the key-value pair for the keepr pod. The value is the serialized data of the pod, which is encoded using Protocol Buffers.
This data might look somewhat like this:
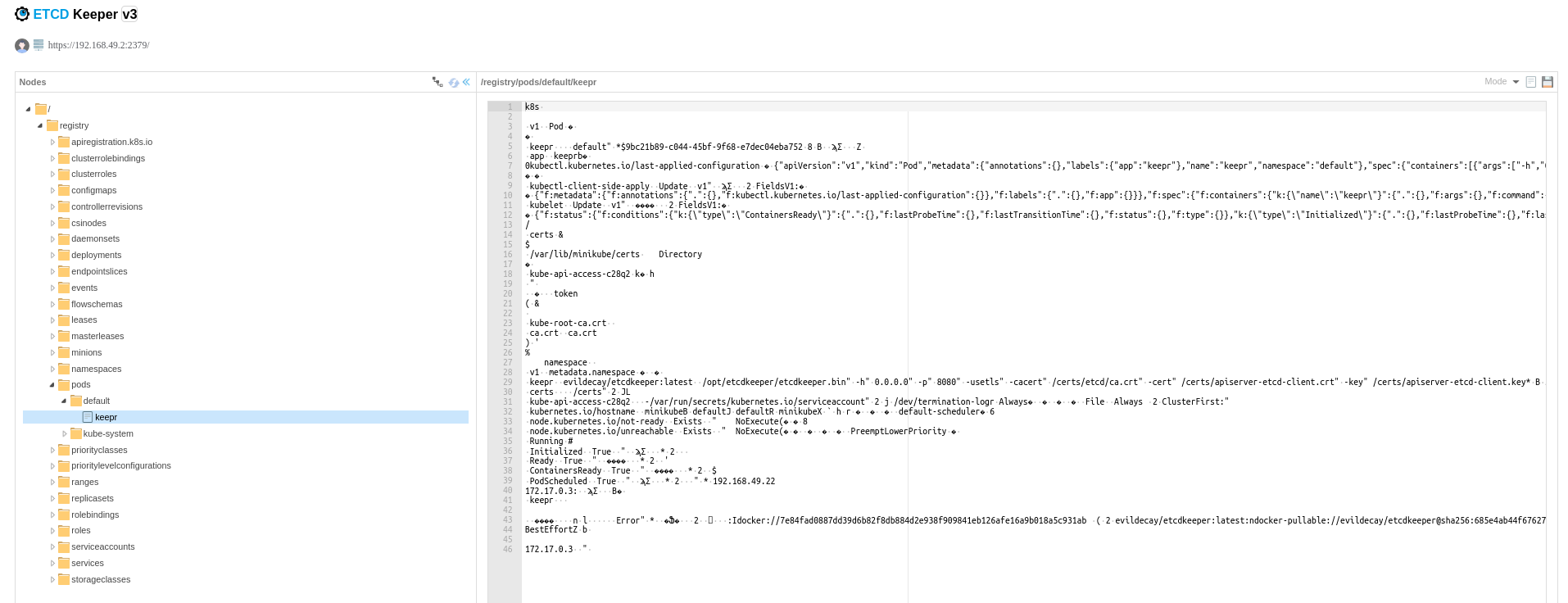
This is actually a serialized Protocol Buffers message. The string begins with k8s, which is the prefix for all Kubernetes objects stored in etcd.
Decoding this data requires a reasonable understanding of the Protocol Buffers language and the Kubernetes data model. You will need the Protocol Buffers definition (.proto file) that was used to serialize this data
A simpler alternative would be to use the Kubernetes API or kubectl to fetch this information, which handles the deserialization for you and presents the data in a human-readable format. For example, to get the configuration of the keepr pod, you could use:
kubectl get pod keepr -o yaml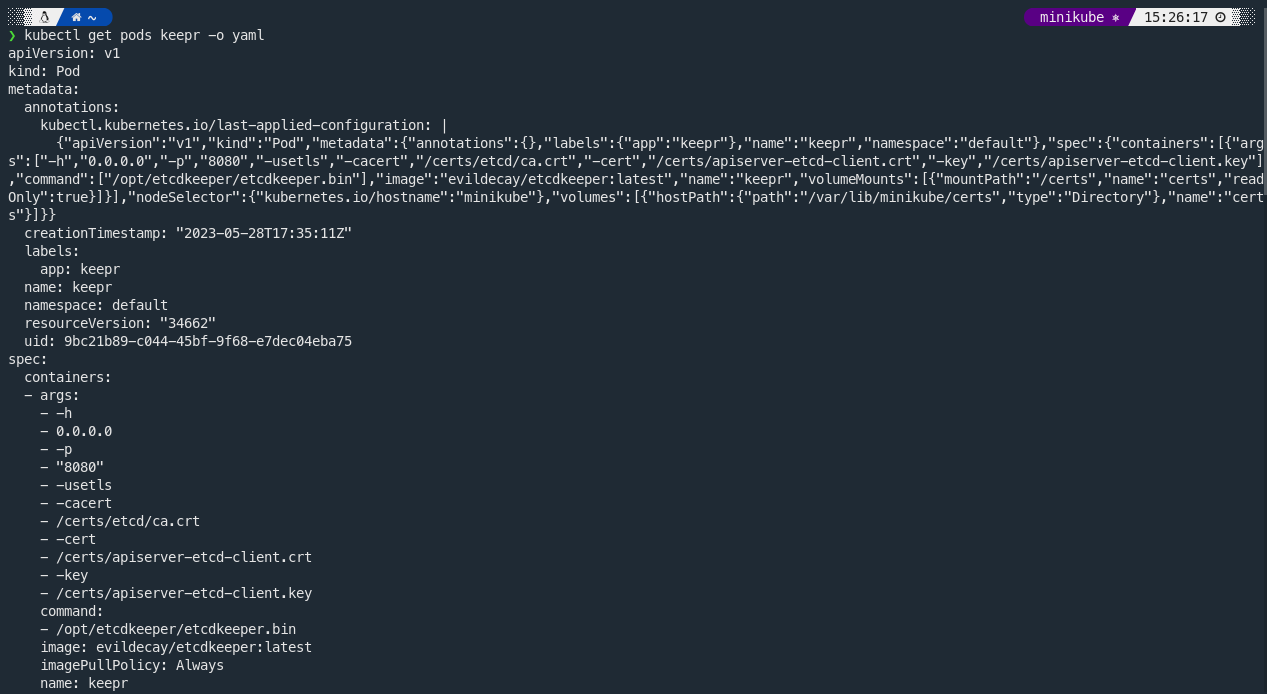
In summary, the data in etcd is not meant to be directly human-readable. It is structured for efficiency and fault-tolerance, using tools like Protocol Buffers and Write-Ahead Logging. The Kubernetes API server and tools like kubectl and etcdkeeper handle the task of presenting this data in a way that's understandable to users.
etcd's Leader Election Mechanism
etcd, as a key component of Kubernetes, relies heavily on the idea of "leader election." But what does it mean, and why is it important? Let's break it down in a simple way:
Understanding the Basics: Leader and Followers
In a group of etcd nodes (we call this a 'cluster'), one node is elected as the 'leader,' and the rest become 'followers.' It's just like a team with a team lead - there's one leader, and the rest of the team follow the leader's instructions. This is crucial because it ensures everyone in the team (or every node in the cluster) agrees on what data is stored and where it is stored.

So How is The Leader Elected?
When a cluster is started, every node begins as a follower. Think of it as a team without a leader initially. But we can't continue without a leader, right? So, one of the followers steps up and declares itself as a candidate for the leader role, like someone nominating themselves in a team meeting.
This candidate then asks for votes from all other nodes, similar to a voting process in an election. The nodes will vote based on certain rules - for example, they won't vote if they have a more recent version of data than the candidate. If the candidate gets the majority of votes, congrats, we have a new leader!
The Role of The Leader
Once a leader is elected, it's responsible for handling all the write operations. If there's any new data to be stored or any changes to the existing data, it's the leader's job to manage it. The leader also ensures all the followers have the latest data.
The leader regularly sends 'heartbeats' (simple signals) to the followers. If a follower stops receiving these heartbeats, it assumes the leader might have failed and starts a new election.
How Does etcd Handle Reads and Writes?
For writing data, the leader first writes it to its own log and then shares it with the followers. Once the majority of nodes have this new data, it's considered successful.
Read requests, on the other hand, are usually handled by the leader to ensure that the most recent data is returned. However, etcd does allow followers to handle read requests in some cases to balance the load.

Conclusion
In this article, we've delved deeper into the workings of etcd, exploring its Write-Ahead Log (WAL) mechanism, Protocol Buffers, and the leader election process. The WAL ensures data durability, preserving entries in the event of system crashes. Protocol Buffers underpin etcd's efficient data handling, enabling fast and reliable serialization/deserialization.
The leader election process is crucial for maintaining consistency across the etcd cluster. In this distributed environment, one node assumes the role of a leader to manage all write operations, ensuring all nodes stay in sync.
By understanding these core concepts, you can gain a greater appreciation of etcd's robustness and reliability in managing Kubernetes state and configuration data.
Stay tuned for the next article in this series where we'll further simplify and explore more features of etcd.